2025.04.15(화)
어제 하루에 다 리뷰하지 못한 1차 미니프로젝트 2일차 리뷰를 시작하겠습니다 !
어제랑 이어지는 이야기이니 바로 시작할게요 ~!

Mission3. 분석 모델 개발
→ 목표 : 전처리한 데이터를 활용해 군집분석을 수행하고, 데이터 탐색 기반 프로파일링을 통해 군집별 특징 정의해보기.
0. 환경설정
(구글 마운트와 경로지정 수행)
1. k-means 모델 (군집분석)
○ k-means 모델
: 비지도학습의 대표적 군집분석을 위한 모델로, 주어진 데이터를 K개의 클러스터로 묶는 알고리즘
→ 장점 : 단순, 빠른 연산 속도 / 단점 : 이상치&노이즈에 민감, 초기 군집 수 설정 중요
1) 데이터 불러오기
data = pd.read_csv(path+'data_sc.csv')→ read_csv() 메소는 pandas인 것을 기억하자.
2) 군집분석
→ 군집분석을 위한 최적의 그룹 k값을 찾아보자.
① 기본 셋팅
: yellowbrick을 import해서 군집분석 해보기.
!pip install yellowbrick
from sklearn.cluster import KMeans
from yellowbrick.cluster import KElbowVisualizer
②-1) 직접 하나씩 다 해보기
# 임의의 군집 수 설정
k=3
# 모델 만들기 (random_state=2024, n_init=10으로 설정)
model_1 = KMeans(n_clusters=k, random_state=2025,n_init=10)
# 데이터 학습
model_1.fit(data)
# 성능지표 확인하기
print(model_1.inertia_)
print(model_1.score(data))→ 해당 과정들을 거쳐 하나하나씩 수행해보지만, k가 늘어난다고 무조건 좋은 모델이라고 설명하기는 어렵다.
②-2) Elbow Method를 이용해 k값 설정
: yellowbrick의 k-Elbow Method를 활용해 최적의 k값을 구하기.
# 1. 모델 선언(random_state=2025, n_init = 10 으로 설정)
model_E = KMeans(random_state=2025,n_init=10)
# 2. KElbowVisualizer 에 k-means 모델과 k값 넣어서 만들기
Elbow_M = KElbowVisualizer(model_E,k=(2,21))
# 3. Elbow 모델 학습하기(fit)
Elbow_M.fit(data)
# 4. Elbow 모델 확인하기
Elbow_M.show()→ 해당 코드를 실행하면 아래와 같은 그래프가 그려지며, score 등을 고려한 최적의 k값을 정해서 알려준다.
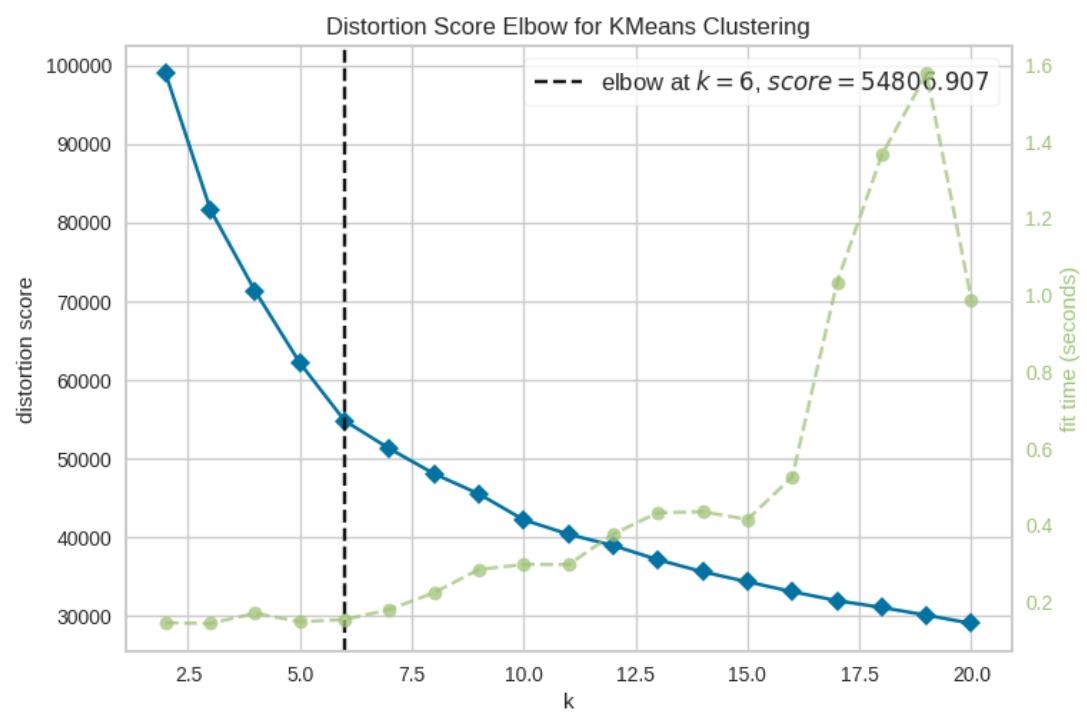
③ 최적의 k값으로 모델링
: Elbow Method를 통해 얻은 최적의 k값으로 모델링 진행
# 1.최적의 k 값으로 군집 수 선택 (k4에 할당)
k4=6
# 2. 모델 만들기 (model_B 에 할당)
model_B = KMeans(n_clusters=k4, random_state=2025, n_init=10)
# 3. 스케일링 된 데이터에 학습
model_B.fit(data)
# 4. 클러스터링 된 결과 각 데이터가 몇번째 그룹에 속하는지 확인 및 저장(.predict)
cluster = model_B.predict(data)
# 1. 예측 결과를 데이터프레임으로 변환
cluster = pd.DataFrame(cluster, columns = ['cluster'], index=data.index)
# 2. 원본 데이터와 합쳐서 result 변수로 저장
result = pd.concat([data0, cluster], axis=1 )
# 3. 예측 결과는 카테고리 타입으로 변경
result['cluster'] = pd.Categorical(result['cluster'] )
result.head()
# 4. 결과 저장
result.to_csv('result_박재욱_2.csv', index=False)→ 분류된 군집을 원본 데이터에 합쳐서 만든 데이터프레임을 저장하고, 이후에 진행될 프로파일링에 사용한다.
2. 프로파일링
: 군집의 구조와 내용을 분석하고 도메인 및 현업업무의 '추론'을 바탕으로 분석의 결과를 적용 가능하도록 하는 과정.
☆ 프로파일링을 위해선 군집간의 차이를 도메인 및 업무 관점에서 해석해야한다.
1) 컬럼 확인하기
: info()와 head()같은 메소드를 이용해 DataFrame의 타입과 유형을 파악한다.

2) 컬럼 별 시각화
① 'AGE' 열 (범주형 데이터 시각화 방법 대표)
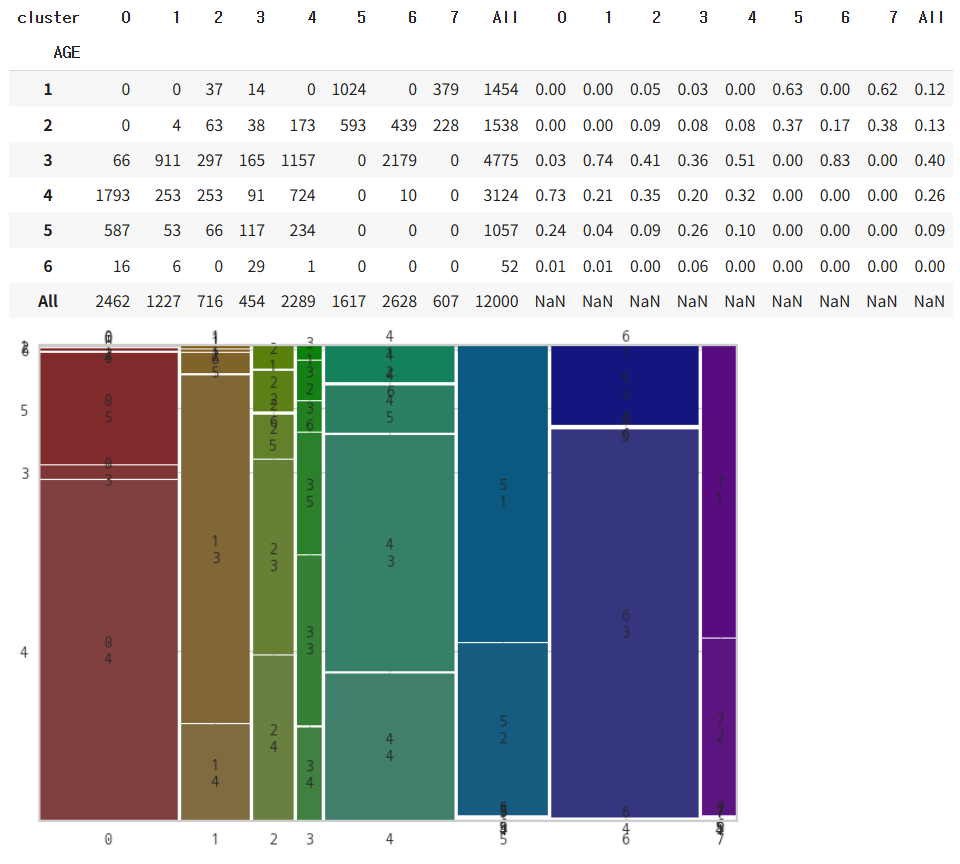
# 'AGE' 열에 대해 crosstab을 활용해서 clust별 범주별 합계를 확인
feature = 'AGE'
# df1 : 범주별 합계
pro_df1 = pd.crosstab([result[feature]], result['cluster'], margins=True)
# df2 : 범주별 비율
pro_df2 = pd.crosstab([result[feature]], result['cluster'], margins=True, normalize='columns')
pro_df2 = pro_df2.round(3)
# 합계와 비율 데이터 합치기 (pd.concat())
pro_df = pd.concat([pro_df1, pro_df2], axis=1)
# pro_df 확인
display(pro_df)
# 시각화
mosaic(result.sort_values('cluster'), [ 'cluster', feature])
plt.show()→ 범주형 데이터에 대한 분석 함수를 적용하여서, 각 군집이 어떠한 특징이 있는지는 한 눈에 볼 수 있게 시각화한다.
② '소득' 열 (수치형 데이터 시각화 방법 대표)
# '소득' 열에 대해 각 clust 별 min,max,mean,median 통계 값으로 확인
# groupby 와 agg() 메소드를 활용
feature = '소득'
display(result[['cluster',feature]].groupby(['cluster']).agg(['max','min','mean','median']))
# 시각화
sns.barplot(x='cluster', y=feature, data=result, palette='cool')
plt.show()→ 수치형 데이터에 대한 분석 함수를 적용하여서, 각 군집의 특징을 한 눈에 볼 수 있게 시각화한다.

③ 나머지 컬럼에다가 수치형/범주형 데이터에 적합한 시각화 방법 적용
→ 범주형 : 등록, 성별, 상품타입, 교육수준, 고용상태, 결혼여부, VOC, 타 상품 보유 현황, 갱신 인센티브, 자동차, 거주지사이즈, 갱신, 지역, 온라인방문빈도, 판매채널
→ 수치형 : Willingness to pay/stay, 월 납입액, 총지불금액
3) 결과 정리
○ 예시) 7번 클러스터
① 시각화 데이터 확인

특징 ① : 나이대가 20~30대로 이루어진 그룹이다.
→ 'AGE' 컬럼에서 20대가 62%, 30대가 38%로 구성
→ 젊은 사람들로 구성되어 있는 군집이다.
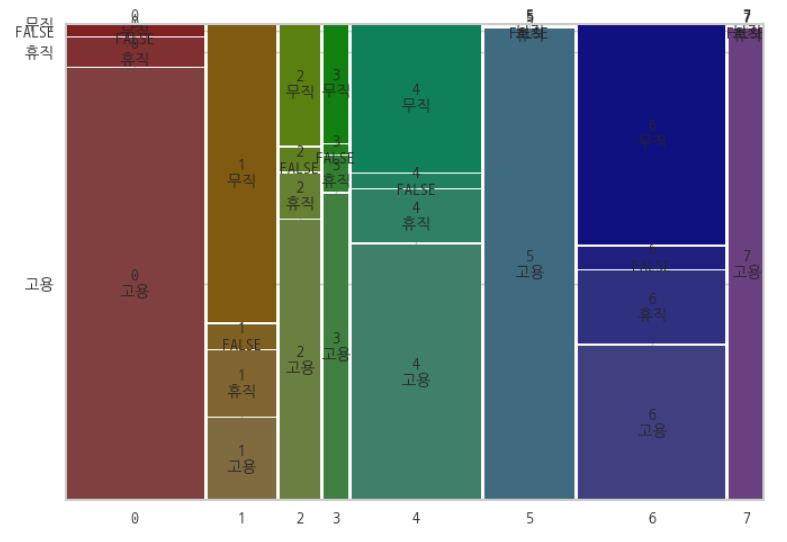
특징 ② : '고용상태'가 모두 '고용'이다.
→ 모두 고용 중인 상태로, 보험료를 지불할 충분한 능력이 될 것이다.
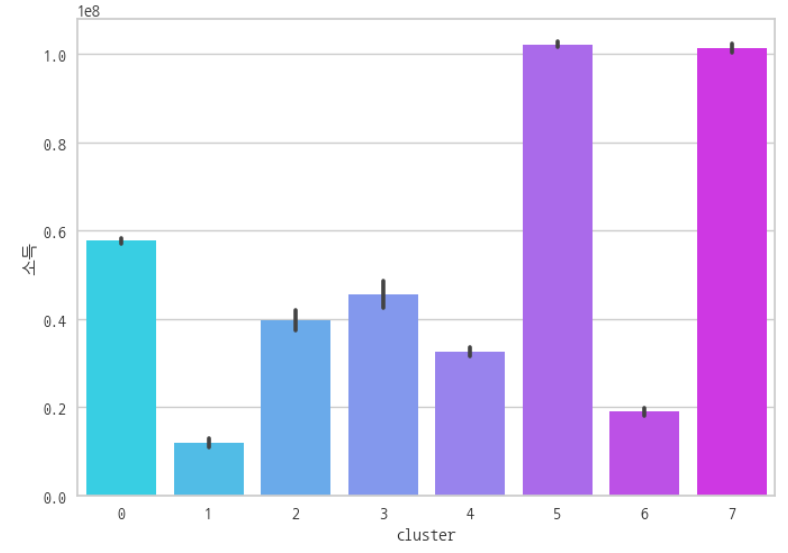
특징 ③ : '소득' 수준이 최상위 군집이다.
→ 소득 수준이 최상위이므로, 보험료를 지불할 충분한 능력이 있을 것이다.

특징 ④ : '결혼여부'에서 기혼 비율이 높다.
→ 기혼이 74%, 미혼이 26%로 구성
→ 기혼자가 많은 군집이다.
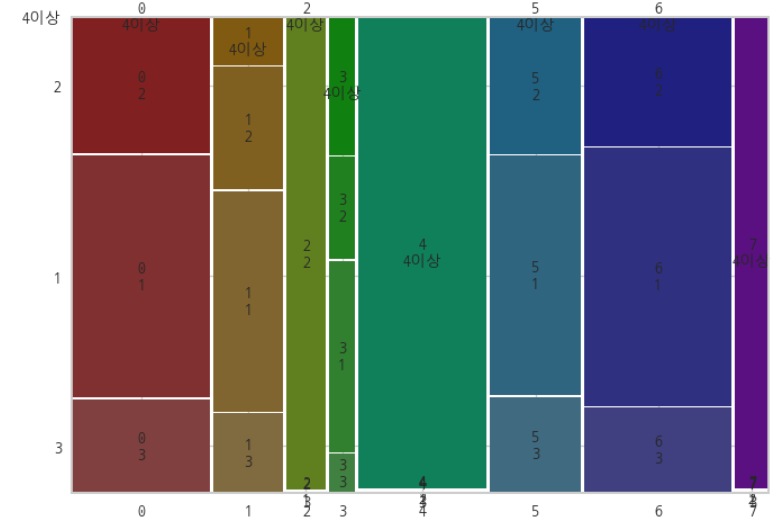
특징 ⑤ : '타 상품 보유 현황'이 모두 '4이상'이다.
→ 보험사 내 다른 금융 상품을 4개 이상 보유하고 있는 이용자로만 이루어진 군집이다.
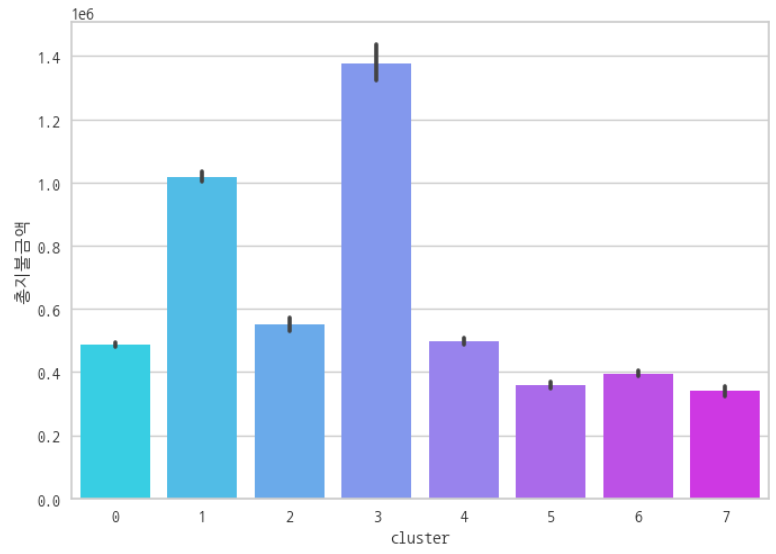
특징 ⑥ : '총지불금액' 값의 평균이 최하위이다.
→ 보험사에서 지급되는 '의료비 청구 이후 심사 후 지급 금액'을 의미하는 '총지불금액'이 가장 적은 군집이다.
→ 보험료를 가장 적게 청구하여 받는 군집이다.
팀에서 제가 맡아서 분석을 수행한 군집이었지만,
정말 특징이 비교적 뚜렷하고, 특징이 아주 흥미로운 군집이었습니다.

그럼 본격적으로 군집을 보고 인사이트를 얻어볼까요?
② 시각화 데이터 기반 추론 수행
→ 모두 고용인 상태의 젊은 나이대 사람으로 구성된 지불 능력이 보장된 군집이다.
→ 소득의 평균이 타 군집과 비교해 가장 높은 군집이기에 보험료를 지불할 능력이 충분한 군집이다.
→ 기혼 비율이 높고, 보험사 내 금융 상품 4개 이상 가입된 이용자이기에 가족 보험과 자녀 보험, 저축에 관심이 있을 것이다.
→ 나이가 젊고, 총 지불 금액은 최하위이므로 건강하고 보험료 수령이 가장 적을 것이다.
③ 추론을 바탕으로 마케팅 방안 수립
→ 수령하는 청구보험료가 적으므로, 지급 보험료가 낮은 고객 대상으로 무사고 캐시백 상품을 제공으로 갱신 유도 가능
→ 가족들의 보험 상품이나 금융 상품 등 여러 개의 상품을 이용하는 고객 대상으로 리워드 제공으로 상품 가입 유도 가능
→ 젊고 수입이 많은 고객이 많으므로 투자를 목적으로 하는 보험 상품 홍보 시 효과 극대화
자, 길고 긴 첫 미니프로젝트의 리뷰가 끝났습니다 ~ !!!

와 정말 많은 내용을 배우고, 적용해보는 시간을 가진 것 같습니다 !
본문 마지막에 보이는 내용과 같이 군집분석을 통해 얻은 인사이트를 바탕으로
최종적으로 마케팅 방안까지 수립해 보았습니다.
이게 저희가 머신러닝을 사용하는 가장 궁극적인 목적일 것입니다.
그리고 이후에 서로 도출한 인사이트와 마케팅 방안들을 팀별로 나누고 토의해보는 시간을 가졌습니다.
서로 바라보는 시각이 다르고, 생각하는 방향들이 많이 다르다는 것을 느꼈습니다 !
인공지능을 이용해서 정보를 정리하고 탐색하기는 하지만,
그래도 마지막에는 사람의 의견과 생각이 쓰이는 것을 느꼈습니다.
물론, 특정 데이터에는 그 데이터만으로 결과를 낼 수 있는 것도 있을테지만, 그래도 사람이 빠질 순 없는거 같습니다.
이렇게 2주 동안 배웠던 내용을 실제로 사용해보니,
내가 2주 동안 헛된걸 배우지 않았구나 를 느낄 수 있는 시간이었습니다 !!
내용이 많고, 진도가 많이 빠르지만 그래도 열심히 복습하고 되새겨보며 열심히 공부하겠습니다 !
여러분은 해당 방법을 보고 어떤 생각이 떠오르시나요? :D
오늘도 고생하셨습니다 !

'KT에이블스쿨 > 수업 복습 정리' 카테고리의 다른 글
| [KT에이블스쿨]_생성형AI_2일차_2025.04.21(월) (1) | 2025.04.21 |
|---|---|
| [KT에이블스쿨]_생성형AI_1일차_2025.04.18(금) (0) | 2025.04.18 |
| [KT에이블스쿨]_(1차)미니프로젝트_2일차(1)_2025.04.15(화) (0) | 2025.04.15 |
| [KT에이블스쿨]_(1차)미니프로젝트_1일차_2025.04.14(월) (0) | 2025.04.14 |
| [KT에이블스쿨]_머신러닝(3)_2025.04.09(수) (0) | 2025.04.12 |