20205.04.15 (화)
오늘은 1차 미니프로젝트 2일차 !
어제 너무 늦었기 때문에 오늘은 일찍 출발했습니다.
오늘은 다른 곳에서 조금 멀리 출발했기 때문에 역시 일찍 도착했습니다.
(원래 가까운 순서대로 늦어지는거 아시죠? ㅇㅅㅇ;;a)
는 농담이고, 정말 안 늦으려고 일찍 출발했습니다...ㅎㅎㅎ..

어제 조금 늦어서 찍지 못했던 KT탄방타워를 오늘 찍었습니다 !
날도 아주 좋아서 이쁘게 잘 찍혔네요 ! ㅎㅎ

탄방역 1번 출구로 나오면 바로 앞에 있는 건물입니다.
혹시 방문하실 예정이신 분은 참고해주세요 ~ :D
다만 오늘은 점심식사를 탄방동 홍콩반점가서 해서 사진을 못 찍었네요 !
하지만 깔끔하고 맛있었습니다.
다른 곳이랑 다른게 고기짜장에 고기 양이 엄청 많더라구요 ...?!
정말 놀랐습니다 ..!
다음에 재방문해서 먹어보고 싶은 비주얼이었습니다 :)

자 그럼 오늘도 이제 본격적으로 미니프로젝트에 대해 리뷰해보겠습니다 !
오늘은 스스로 작성해보았던 데이터분석, 데이터전처리, 군집 분석 순으로 이야기 해보겠습니다 ~

Mission 1. 탐색적 데이터 분석
○ 미션 이해하기
- K보험사 직원으로서 효과적인 마케팅 전략을 완성시키기 위해 데이터 기반 마케팅 시작
- 고객 데이터를 마케팅 전량에 반영하고 고객별 적절한 마케팅 Action을 주는 것이 목표
- 고객별 마케팅 방법을 반영하기 위해서는 고객을 Segment 해야 하는데, 어떻게 고객을 분류할까?
→ 군집분석을 기반으로 고객 Segment 개발을 위해 주요 변수를 선정하고 데이터 탐색하기
0. 환경설정(경로설정)
→ 구글 드라이브에 연결하여 마운트를 진행하고, 코드 작성 중 데이터를 불러올 경로를 지정한다.
(너무 많이 다뤄서 방법과 코드는 생략!)
1. 데이터 불러오기
import numpy as np
import pandas as pd
import seaborn as sns
import os
# 한글세팅
# 1. 나눔고딕 폰트 설치
!apt-get -qq update
!apt-get -qq install -y fonts-nanum
# 2. 런타임에 폰트 캐시 갱신
import matplotlib.font_manager as fm
import matplotlib.pyplot as plt
import matplotlib as mpl
font_dirs = ['/usr/share/fonts/truetype/nanum']
font_files = fm.findSystemFonts(fontpaths=font_dirs)
for font_file in font_files:
fm.fontManager.addfont(font_file)
# 3. 폰트 이름 확인 후 설정
nanum_font_name = fm.FontProperties(fname=font_files[0]).get_name()
print(f"설정된 폰트 이름: {nanum_font_name}")
# matplotlib에 폰트 반영
mpl.rc('font', family=nanum_font_name)
mpl.rcParams['axes.unicode_minus'] = False→ 후반에 분류형 데이터 시각화를 위해서 한글을 출력할 수 있도록 한글 사용 세팅
data = pd.read_csv(path+'customers_seg.csv')
data.head()→ 고객 데이터를 불러오고, 확인하기 위해 상위 5개 항목 출력
2. 데이터 기초 정보 확인하기
: 불러온 데이터셋의 기초 정보를 확인
→ data.head(), data.tail(), data.shape, data.info(), data.describe(), data.columns 과 같은 메소드로 기초 정보 확인
3. 주요 변수 선정 및 탐색
→ 군집화에 사용할 주요 변수를 탐색하고 선정한다.
① 도메인 내 주요 정보 항목 : Willingness to pay/Stay, 소득, 월 납입액, 타상품 보유 현황, 총지불금액
② 분석가 선정 컬럼 : AGE, 고용상태, 교육수준, 상품타입, 거주지사이즈, 자동차
○ 분석가 선정 컬럼 확인하기
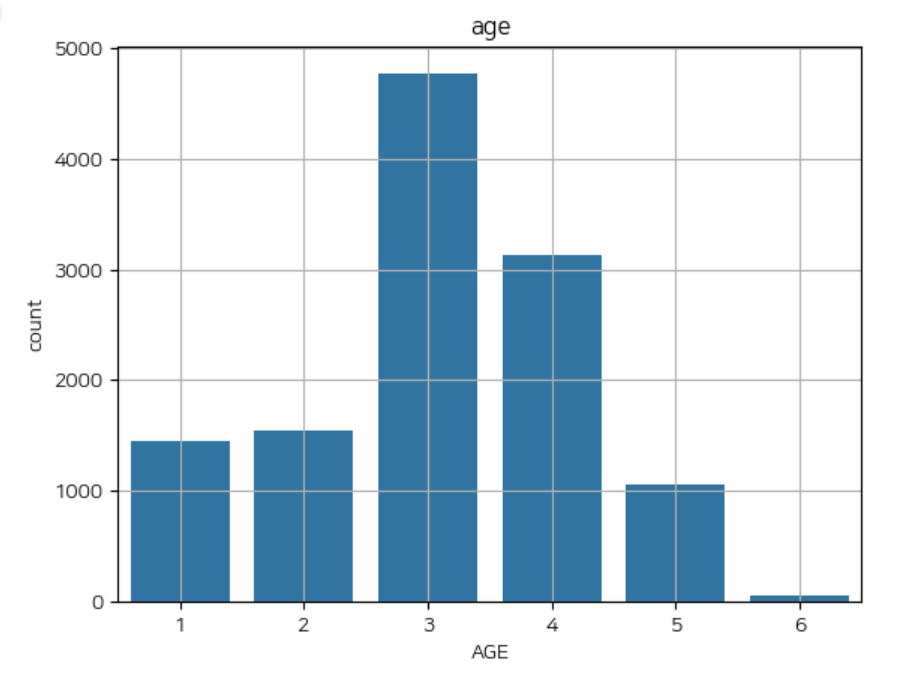
1) AGE
# 범주별 비율 탐색
data['AGE'].value_counts(normalize = True).sort_index()
# 범주 시각화
sns.countplot(x='AGE',data=data)
plt.title('age')
plt.grid()
plt.show()→ 위 코드를 통해 비율을 확인하고, 분포를 시각화해 확인할 수 있다.
2) 고용상태
# 비율로 표현
data['고용상태'].value_counts(normalize = True).sort_index()
employment_ratio = data['고용상태'].value_counts(normalize=True).sort_index() * 100
employment_ratio = employment_ratio.round(2)
employment_ratio_df = employment_ratio.reset_index()
employment_ratio_df.columns = ['고용상태', '비율(%)']
display(employment_ratio_df)→ 비율로 표현하여 확인
print(data['고용상태'].unique())
print(data[data['고용상태'] == False])→ FALSE 문자가 Boolean형식인지 문자형식인지 확인
#데이터 시각화
sns.countplot(x='고용상태',data=data)
plt.title('고용상태')
plt.grid()
plt.show()

3) 나머지 Columns에도 동일하게 진행
: 교육수준, 상품타입, 거주지사이즈, 자동차
○ 도메인 주요 항목 컬럼 탐색하기
1) WTP (Willingness to pay/Stay)
→ 연속형/수치형 컬럼이기 때문에 hisyplot으로 데이터 확인
plt.figure(figsize=(12,8))
# bins = 30, kde = True로 설정
## bins : 데이터를 나누는 구간(막대)의 개수
## kde(커널 밀도 추정) : 부드러운 곡선으로 추정해서 시각화
sns.histplot(data['Willingness to pay/Stay'],bins=30,kde=True)
plt.grid()
plt.show()
data.describe()→ 히스토그램을 플롯하여 데이터 분포를 확인한다.
→ describe() 메소드를 이용해 수치형 데이터의 대푯값들을 확인한다.
2) 수치형 컬럼들에 동일하게 적용
→ 소득, 월 납입액, 총지불금액
3) 타 상품 보유 현황
→ 문자형/범주형 컬럼이기 때문에 범주 비율로 데이터 확인
타상품_보유_ratio = data['타 상품 보유 현황'].value_counts(normalize=True).sort_index() * 100
타상품_보유_ratio = 타상품_보유_ratio.round(2)
타상품_보유_ratio_df = 타상품_보유_ratio.reset_index()
타상품_보유_ratio_df.columns = ['타 상품 보유 현황', '비율(%)']
display(타상품_보유_ratio_df)→ 구해진 비율을 퍼센트로 변환하고 출력한다.
● Mission 1 결론
- 수치형 컬럼 외에도 object 형태 컬럼 존재
- 수치형 컬럼은 단위가 다르기에 스케일링 고려 필요
- 범주형 컬럼은 인코딩 필요
Mission 2. 데이터 전처리
○ 미션 이해하기
- 보험사 지원으로서 데이터 기반 마케팅을 시작
- 고객별 마케팅을 계획하기 위해, 군집 분석 기반으로 고객 Segment 개발이 목표
→ 군집 분석을 기반으로 하는 고객 Segment 적용 전 주요 데이터 전처리 수행
0. 환경설정 (경로설정)
→ (이전 과정에서와 동일)
1. 범주 인코딩
# 1. data를 data_choice 변수에 copy
data_choice = data[['Willingness to pay/Stay','소득', '월 납입액', '타 상품 보유 현황',
'총지불금액','AGE', '고용상태', '교육수준', '상품타입', '거주지사이즈', '자동차']].copy()
# 2. col 에 선정한 11개 변수를 리스트로 할당
# [참고] 11개 변수: 'AGE', '고용상태', 'Willingness to pay/Stay', '상품타입',
# '교육수준', '소득', '월 납입액','타 상품 보유 현황', '총지불금액', '거주지사이즈','자동차'
col = list(data_choice.columns[:])
# 3.data_choice 변수에 col 할당 후 data_choice 데이터를 확인
print(data_choice)→ 활용할 주요 변수만 분리하여 원본 데이터에 영향이 없게 복사본을 만들어둔다.
○ 범주형 컬럼 처리하기
1) 고용상태
data_choice['고용상태'].value_counts()
# 인코딩
data_choice['고용상태'] = np.where(data_choice['고용상태'] == '고용', 1, 0)
# 확인
data_choice.head()→ 원래 이전에 배웠던 인코딩에는 Label Encoding과 One-Hot Encoding이 있지만,
np.where()와 같은 메소드로도 인코딩 메소드와 같은 효과를 낼 수 있다.
※ 때론 이렇게 간단하게 인코딩 하는 것이 편리할 때도 있다.
2) 범주형 데이터에 동일하게 적용하기
→ 상품타입, 교육수준, 타 상품 보유 현황, 거주지사이즈, 자동차
2. 스케일링
: Standard Scaling을 이용해 수치형 데이터를 스케일링 진행
# 1. standard-scaler import
from sklearn.datasets import load_iris
import pandas as pd
from sklearn.preprocessing import StandardScaler
# 2. scaler라는 변수에 StandardScaler 입력
scaler = StandardScaler()
# 3. 'data_choice'을 fit_transform 하여 'data_sc'로 저장
# 단, DataFrame을 스케일링하면, 결과가 Numpy array로 나온다.
# 그래서 DataFrame으로 다시 변환할 필요가 있다. (이때 칼럼 이름 필요)
scaler.fit(data_choice)
data_sc_nondf = scaler.transform(data_choice)
data_sc = pd.DataFrame(data=data_sc_nondf, columns=data_choice.columns)→ StandardScaler()를 객체에 생성해주고 스케일링을 진행한다.
→ 하지만 반환되는 데이터는 Numpy Array이기 때문에 다시 DataFrame으로 변환시킨다.
● Mission 2 결론
- 군집화 모델링을 위해 범주형, 수치형 데이터 컬럼의 전처리가 필요
- 범주형은 수치형으로 변환하기 위해 인코딩을 진행하고 난 후에 스케일링 진행
오늘 군집 분석까지 다 해보려고 했으나....
카페에서 하는 중인데 배터리가 다 되가는 관계로....
(절대 하기 싫은거 아님. 진짜임.)
마지막 전처리된 데이터로 군집 분석을 진행하는 단계는 내일 이어서 리뷰하겠습니다 !
어우 이렇게 복습하다보니 이틀동안 정말 많은 분량의 학습을 진행한거 같습니다..!!
먼저 후기를 작성하자면 이번 미니 프로젝트는 그동안 배웠던 내용을 실제로 적용해볼 수 있는 시간이었습니다.
제가 배웠던 내용이 실제로 사용되는 것을 보니 데이터 분석이 가시화 되면서 다시 힘내서 공부할 수 있는 힘을 얻은 듯 합니다 !

(화내는게 아니라 열심히 공부할 의지를 표현중 입니다. 진지합니다.)
정말 어렵기도 하고 힘들기도 한 시간이었지만, 그래도 데이터 분석 실무를 경험하고 나니
공부에 대한 목적성을 다시 다질 수 있는 귀중한 시간이었습니다 ! :D

어제 못 찍었던 조 사진도 찍고 왔습니다 !
다들 항상 온라인 너머로만 봐서 초반에는 조금 어색한 시간도 있었지만,
많이 이야기하고 미니프로젝트를 진행하면서 자연스럽게 친해지고 많이 이야기할 수 있었습니다. ㅎㅎ
다들 너무 고생하셨어요 ㅠㅠㅠ
이런 좋은 과정과 세션을 준비해주신 KT에이블스쿨 최고 ! >.ㅇ
저도 이만 들어가 쉬고 또 내일 공부할 체력을 충전하겠습니다 !
이 글을 보고 있는 모두들 오늘도 고생하셨습니다 !
화이팅 !
:D

'KT AIVLE School > KT에이블스쿨 (7기 DX트랙)' 카테고리의 다른 글
| 2차 미니프로젝트 [KT 에이블스쿨 7기] 2025.04.29(화) (1) | 2025.04.30 |
|---|---|
| 1차 미니프로젝트 (3일차) [KT 에이블스쿨 7기] 2025.04.16(수) (0) | 2025.04.26 |
| 1차 미니프로젝트 (2일차[2]) [KT 에이블스쿨 7기] 2025.04.15(화) (2) | 2025.04.18 |
| 1차 미니프로젝트 (1일차) [KT 에이블스쿨 7기] 2025.04.14(월) (0) | 2025.04.14 |
| Opening Day [KT 에이블스쿨 7기] 2025.03.25(화) (0) | 2025.04.11 |